Квест → Как хакнуть форму
Попытались: 820
Прошли: 77
Прошли: 77
Квест вновь доступен для прохождения !

Практически каждый PHP-разработчик когда-нибудь парсил данные из интернета. Часто нам нужны какие-то данные, которые доступны только на каком-то сайте, и мы хотим вытащить эти данные и сохранить их где-нибудь. Это похоже на то, что мы открываем браузер, ходим по ссылкам и копируем данные, которые нам нужны. Но то же самое может быть автоматизировано с помощью скрипта. В этом статье, я покажу вам путь, как вы можете увеличить скорость вашего парсера путём отправки запросов асинхронно.
Мы создадим простой парсер для парсинга информации о фильме со страницы IMDB:
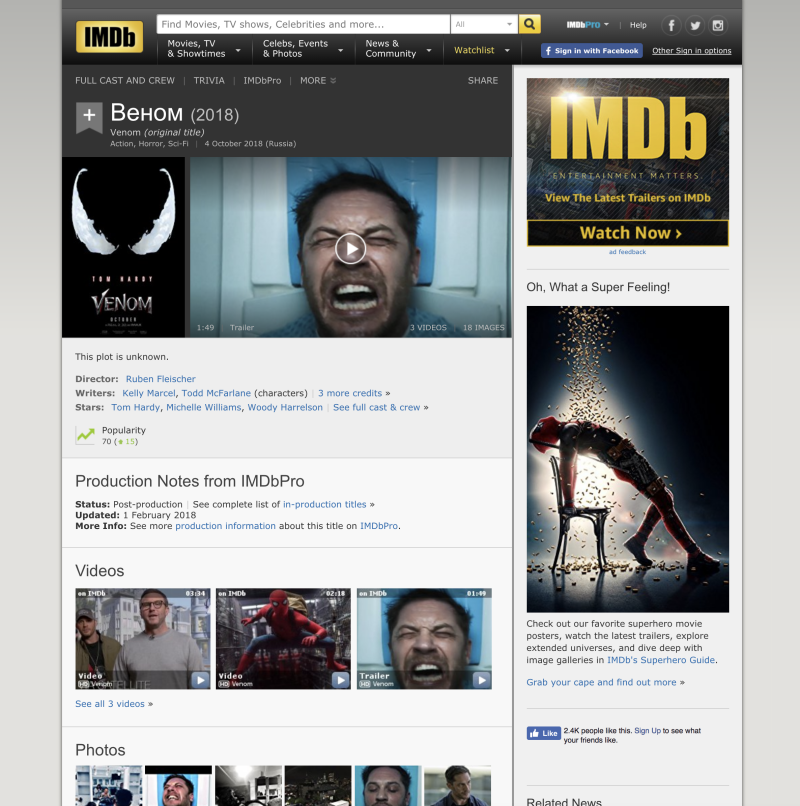
Вот пример страницы фильма Веном. Мы будем обращаться к этой странице, чтобы получить:
IMDB не дает никаких публичных API, поэтому, если нужна информация такого рода, мы должны вытащить её с сайта.
Почему мы должны использовать ReactPHP и отправлять запросы асинхронно? Короткий ответ заключается в скорости. Допустим, что мы хотим разобрать все фильмы с страницы Coming Soon: 12 страниц, по странице на каждый месяц предстоящего года. Каждая страница имеет около 20 фильмов. Так что в общем, мы собираемся сделать 240 запросов. Отправка этих запросов один за другим, может занять некоторое время...

А теперь представьте, что мы можем выполнить эти запросы одновременно. Таким образом, парсинг будет значительно быстрее. Давайте попробуем.
Прежде чем мы начнем писать парсер, нам нужно установить необходимые зависимости через Composer.
Мы собираемся использовать асинхронный http-клиент под названием buzz-react -- библиотеку, написанную Christian Lück. Это простой PSR-7 http-клиент для экосистемы ReactPHP.
composer require clue/buzz-react
Для того, чтобы удобно "ходить" по DOM я использую Symfony DomCrawler Component:
composer require symfony/dom-crawler
CSS-селектор для DomCrawler позволяет использовать jQuery-селекторы:
composer require symfony/css-selector
Теперь мы можем приступить к программированию. И начнём мы с этого:
use Clue\React\Buzz\Browser; $loop = React\EventLoop\Factory::create(); $client = new Browser($loop); // ...
Мы создаём экземпляр цикла событий(event loop) и http-клиент. Следующий шаг - отправка запросов.
Публичный интерфейс основного класса клиента Clue\React\Buzz\Browser очень прост. Он имеет набор методов, названия которых соответствуют методам http: get(), post(), put() и так далее. Каждый метод возвращает "обещание"(promise). В нашем случае, чтобы запросить страницу, мы можем использовать метод get($url, $headers = []):
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody() . PHP_EOL;
});
Приведенный выше код просто выводит запрошенную страницу на экране. Когда ответ получен, отрабатывает "обещание" с переданным экземпляром Psr\Http\Message\ResponseInterface. Таким образом, мы можем обработать ответ внутри обратного вызова.
В отличие от ReactPHP HTTPClient,
clue/buzz-reactбуферизирует ответ и запускает "обещание" после того, как весь ответ получен. На самом деле, это поведение по умолчанию, и вы можете изменить его, если вам нужен потоковый ответ.
Как видите, весь процесс парсинга очень прост:
Страницы, которые нам нужны, не требует какой-либо авторизации. Если мы посмотрим исходный код страницы, мы увидим, что все данные, которые нам нужны, уже есть в формате HTML. Задача очень простая: нет авторизации, нет никаких форм или AJAX-вызовов. Иногда анализ самой страницы и выявление мест с данными занимает в несколько раз больше времени, чем написание парсера, но не в этот раз.
После того как мы получили ответ, мы готовы начать обход DOM. И здесь вступает в игру Symfony DomCrawler. Чтобы начать извлечение информации, мы должны создать экземпляр Crawler`а. Его конструктор принимает строку HTML:
use \Symfony\Component\DomCrawler\Crawler;
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
});
Внутри обработчика мы создаём экземпляр Crawler и передаём ему ответ, приведя его к строке. Теперь мы можем использовать jQuery-подобные селекторы, чтобы извлечь необходимые данные из HTML.
Название может быть взято из тега Н1:
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
});
Метод filter() используется для поиска элемента в DOM. Затем мы извлекаем текст из этого элемента. Эта строка в jQuery выглядит очень похоже:
vat title = $('h1').text();
Жанры можно получить как текст внутри соответствующих ссылок.

// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
});
Метод extract() используется для извлечения атрибутов и/или значений нода из списка нодов. Здесь (в ->extract(['_text'])) специальный атрибут _text представляет собой значение нода. Описание тоже взято как текстовое значение из соответствующего тега
Немного сложнее с датой выхода:

Как вы видите, он находится внутри тега
, но мы не можем просто извлечь текст из него. В этом случае дата релиза будет Release Date: 16 February 2018 (USA) See more ». И это не то, что нам нужно. Перед извлечением текста из этого DOM-элемента, нам нужно удалить все теги внутри него:
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
// ...
$crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
});
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text());
});
Здесь мы выбираем все теги
из раздела Details. Затем мы в цикле удаляем все дочерние теги. Чтобы получить дату релиза мы выбираем четвертый (с индексом 3) элемент и стягиваем его текст (теперь без остальных тегов).
И последний шаг -- это собрать все эти данные в массив и завершить обработку promise`а:
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
$crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
});
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(2)->text());
});
Самое время собрать всё кусочки вместе. Логику запроса можно вынести в функцию (или класс), чтобы в дальнейшем можно было передавать в него разные URL-адреса. Давайте вынесем класс Parser:
class Parser
{
/**
* @var Browser
*/
private $client;
/**
* @var array
*/
private $parsed = [];
public function __construct(Browser $client)
{
$this->client = $client;
}
public function parse(array $urls = [])
{
foreach ($urls as $url) {
$this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->parsed[] = $this->extractFromHtml((string) $response->getBody());
});
}
}
public function extractFromHtml($html)
{
$crawler = new Crawler($html);
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
$crawler->filter('#titleDetails .txt-block')->each(
function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
}
);
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(2)->text());
return [
'title' => $title,
'genres' => $genres,
'description' => $description,
'release_date' => $releaseDate,
];
}
public function getMovieData()
{
return $this->parsed;
}
}
В качестве зависимости он принимает в конструкторе экземпляр Browser. Публичный интерфейс очень прост и состоит из двух методов: parse(array $urls)) и getMovieData(). Первый выполняет всю работу: отправляет запросы и обходит DOM. А второй просто получает результаты.
Теперь мы можем попробовать его в действии. Давайте попробуем асинхронно спарсить два фильма:
// ...
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);
$parser = new Parser($client);
$parser->parse([
'http://www.imdb.com/title/tt1270797/',
'http://www.imdb.com/title/tt2527336/'
]);
$loop->run();
print_r($parser->getMovieData());
В приведенном выше фрагменте кода мы создаём парсер и предоставляем ему массив из двух URL-адресов для вытягивания данных. Затем мы запускаем цикл обработки событий. Он будет работать до тех пор, пока все его задачи не будут завершены (пока наши запросы не выполнятся, и мы не стащим всё, что нам нужно). В результате вместо того, чтобы ждать все запросы вообще, мы ждем только самый медленный. Вывод будет следующий:
Array
(
[0] => Array
(
[title] => Venom (2018)
[genres] => Array
(
[0] => Action
[1] => Horror
[2] => Sci-Fi
[3] => Thriller
)
[description] => This plot is unknown.
[release_date] => 4 October 2018 (Russia)
)
[1] => Array
(
[title] => Star Wars: Episode VIII - The Last Jedi (2017)
[genres] => Array
(
[0] => Action
[1] => Adventure
[2] => Fantasy
[3] => Sci-Fi
)
[description] => Rey develops her newly discovered abilities with the guidance of Luke Skywalker, who is unsettled by the strength of her powers. Meanwhile, the Resistance prepares for battle with the First Order.
[release_date] => 14 December 2017 (Russia)
)
)
Вы можете продолжить обработку этих результатов как угодно: сохранять их в разные файлы или записывать в базу. В этой статье основная идея была в том, как сделать асинхронные запросы и парсить ответы.
Наш парсер может быть улучшен путем добавления определенного тайм-аута. Что, если самый медленный запрос будет слишком медленным? Вместо того чтобы ждать, мы можем указать тайм-аут и отменять все медленные запросы. Для реализации отмены запроса я буду использовать таймер цикла обработки событий. Идея заключается в следующем:
Нам нужен экземпляр цикла обработки событий (event loop) внутри нашего Parser`а. Давайте передадим его через конструктор:
class Parser
{
// ...
/**
* @var \React\EventLoop\LoopInterface
*/
private $loop;
public function __construct(Browser $client, LoopInterface $loop)
{
$this->client = $client;
$this->loop = $loop;
}
}
Затем мы можем улучшить метод parse() и добавить необязательный параметр $timeout:
class Parser
{
// ...
public function parse(array $urls = [], $timeout = 5)
{
foreach ($urls as $url) {
$promise = $this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->parsed[] = $this->extractFromHtml((string) $response->getBody());
});
$this->loop->addTimer($timeout, function() use ($promise) {
$promise->cancel();
});
}
}
}
Если $timeout не передан, мы используем по умолчанию 5 секунд. Когда время выдит, он пытается отменить заданные "обещания"(promise). В этом случае, все запросы, которые длятся дольше, чем 5 секунд, будут отменены. Если "обещание" уже запущено (запрос отправлен и выполнен) метод cancel() не возымеет никакого эффекта.
Например, если мы не хотим ждать более 3 секунд, код будет следующем:
parse([
'http://www.imdb.com/title/tt1270797/',
'http://www.imdb.com/title/tt2527336/'
], 3);
Заметка о веб-парсинге: некоторые сайты не любят, когда их парсят. Часто вытягивание данных для личного использования -- это, как правило, ОК. Но постарайтесь избежать сотни одновременных запросов с одного IP. Сайту это может не понравиться и он может вас забанить.
Примеры из этой статьи вы можете найти на GitHub.